Main menu
You are here
Agreguesi i feed
6.6.95: longterm
6.1.142: longterm
5.15.186: longterm
5.10.239: longterm
5.4.295: longterm
Luis Villa: book reports, mid-2025
Some brief notes on books, at the start of a summer that hopefully will allow for more reading.
Monk and Robot (Becky Chambers); Mossa and Pleiti (Malka Older)Summer reading rec, and ask for more recs: “cozy sci-fi” is now a thing and I love it. Characters going through life, drinking hot beverages, trying to be comfortable despite (waves hands) everything. Mostly coincidentally, doing all those things in post-dystopian far-away planets (one fictional, one Jupiter).
Novellas, perfect for summer reads. Find a sunny nook (or better yet, a rainy summer day nook) and enjoy. (New Mossa and Pleiti comes out Tuesday, yay!)
A complex socio-technical system, bounding boldly, perhaps foolishly, into the future. (Original via NASA) Underground Empire (Henry Farrell and Abraham Newman)This book is about things I know a fair bit about, like international trade sanctions, money transfers, and technology (particularly the intersection of spying and data pipes). So in some sense I learned very little.
But the book efficiently crystallizes all that knowledge into a very dense, smart, important observation: that some aspects of American so-called “soft” (i.e., non-military) power are in increasingly very “hard”. To paraphrase, the book’s core claim is that the US has, since 2001, amassed what amounts to several, fragmentary “Departments of Economic War”. These mechanisms use control over financial and IP transfers to allow whoever is in power in DC to fight whoever it wants. This is primarily China, Russia, and Iran, but also to some extent entities as big as the EU and as small as individual cargo ship captains.
The results are many. Among other things, the authors conclude that because this change is not widely-noticed, it is undertheorized, and so many of the players lack the intellectual toolkit to reason about it. Relatedly, they argue that the entire international system is currently more fragile and unstable than it has been in a long time exactly because of this dynamic: the US’s long-standing military power is now matched by globe-spanning economic control that previous US governments have mostly lacked, which in turn is causing the EU and China to try to build their own countervailing mechanisms. But everyone involved is feeling their way through it—which can easily lead to spirals. (Threaded throughout the book, but only rarely explicitly discussed, is the role of democracy in all of this—suffice to say that as told here, it is rarely a constraining factor.)
Tech as we normally think of it is not a big player here, but nevertheless plays several illustrative parts. Microsoft’s historical turn from government fighter to Ukraine supporter, Meta’s failed cryptocurrency, and various wiretapping comes up for discussion—but mostly in contexts that are very reactive to, or provocative irritants to, the 800lb gorillas of IRL governments.
Unusually for my past book reports on governance and power, where I’ve been known to stretch almost anything into an allegory for open, I’m not sure that this has many parallels. Rather, the relevance to open is that these are a series of fights that open may increasingly be drawn into—and/or destabilize. Ultimately, one way of thinking about this modern form of power dynamics is that it is a governmental search for “chokepoints” that can be used to force others to bend the knee, and a corresponding distaste for sources of independent power that have no obvious chokepoints. That’s a legitimately complicated problem—the authors have some interesting discussion with Vitalik Buterin about it—and open, like everyone else, is going to have to adapt.
Dying Every Day: Seneca at the Court of Nero (James Romm)Good news: this book documents that being a thoughtful person, seeking good in the world, in the time of a mad king, is not a new problem.
Bad news: this book mostly documents that the ancients didn’t have better answers to this problem than we moderns do.
The Challenger Launch Decision (Diane Vaughan)The research and history in this book are amazing, but the terminology does not quite capture what it is trying to share out as learnings. (It’s also very dry.)
The key takeaway: good people, doing hard work, in systems that slowly learn to handle variation, can be completely unprepared for—and incapable of handling—things outside the scope of that variation.
It’s definitely the best book about the political analysis of the New York Times in the age of the modern GOP. Also probably good for a lot of technical organizations handling the radical-but-seemingly-small changes detailed in Underground Empire.
Spacesuit: Fashioning Apollo (Nicholas De Monchaux)A book about how interfaces between humans and technology is hard. (I mean clothes, but also everything else.) Delightful and wide-ranging; maybe won’t really learn any deep lessons here but it’d be a great way to force undergrads to grapple with Hard Human Problems That Engineers Thought Would Be Simple.
Jonathan Blandford: Crosswords 0.3.15: Planet Crosswords
It’s summer, which means its time for GSoC/Outreachy. This is the third year the Crosswords team is participating, and it has been fantastic. We had a noticeably large number of really strong candidates who showed up and wrote high-quality submissions — significantly more than previous years. There were a more candidates then we could handle, and it was a shame to have to turn some down.
In the end, Tanmay, Federico, and I got together and decided to stretch ourselves and accept three interns for the summer: Nancy, Toluwaleke, and Victor. They will be working on word lists, printing, and overlays respectively, and I’m so thrilled to have them helping out.
A result of this is that there will be a larger number of Crossword posts on planet.gnome.org this summer. I hope everyone is okay with that, and encourages them so they stay involved with GNOME and Free Software.
ReleaseThis last release was mostly a bugfix release. The intern candidates outdid themselves this year by fixing a large number of bugs — so many that I’m releasing this to get them to users. Some highlights:
- Mahmoud added an open dialog to the game and got auto-download of puzzles working. He also created an arabic .ipuz file to test with which revealed quite a few rendering bugs.
{kind=link}
- Toluwaleke refined the selection code. This was accidentally marked as a newcomer issue, and was absolutely not supposed to be. Nevertheless, he nailed it and has left selection in a much healthier state.
- [ It’s worth highlighting that the initial MR for this issue is a masterclass in contributions, and one of the best MRs I’ve ever received. If you’re a potential GSoC intern, you could learn a lot from reading it. ]
- Victor fixed divided cells and a number of small behavior bugs. He also did methodical research into other crossword editors.
{kind=link}
- Patel and Soham contributed visual improvements for barred and acrostic puzzles
In addition, GSoC-alum Tanmay has kept plugging on his Acrostic editor. It’s gotten a lot more sophisticated, and for the first time we’re including it in the stable build (albeit as a Beta). This version can be used to create a simple acrostic puzzle. I’ll let Tanmay post about it in the coming days.
Coordinates{kind=link}
Specs are hard, especially for file formats. We made an unfortunate discovery about the ipuz spec this cycle. The spec uses a coordinate system to refer to cells in a puzzle — but does not define what the coordinate system means. It provides an example with the upper left corner being (0,0) and that’s intuitively a normal addressing system. However, they refer to (ROW1, COL1) in the spec, and there are a few examples in the spec that start the upper left at (1, 1).
When we ran across this issue while writing libipuz we tried a few puzzles in puzzazz (the original implementation) to confirm that (0,0) was the intended origin coordinate. However, we have run across some implementations and puzzles in the wild starting at (1,1). This is going to be pretty painful to untangle, as they two interpretations are largely incompatible. We have a plan to detect the coordinate system being used, but it’ll be a rough heuristic at best until the spec gets clarified and revamped.
By the NumbersWith this release, I took a step back and took stock of my little project. The recent releases have seemed pretty substantial, and it’s worth doing a little introspection. As of this release, we’ve reached:
- 85KLOC total. 60KLOC in the app and 25KLOC in the library
- 27K words of design docs (development guide)
- 126 distinct test cases
- 33 different contributors. I’m now at 82% of the commits and dropping
- 6 translations (and hopefully many more some day)
- Over 100 unencumbered puzzles in the base puzzle sets. This number needs to grow.
All in all, not too shabby, and not so little anymore.
A Final RequestCrosswords has an official flatpak, an unofficial snap, and Fedora and Arch packages. People have built it on Macs, and there’s even an APK that exists. However, there’s still no Debian package. That distro is not my world: I’m hoping someone out there will be inspired to package this project for us.
Code of Conduct Committee: Transparency report for May 2025
GNOME’s Code of Conduct is our community’s shared standard of behavior for participants in GNOME. This is the Code of Conduct Committee’s periodic summary report of its activities from July 2024 to May 2025.
The current members of the CoC Committee are:
- Anisa Kuci
- Carlos Garnacho
- Christopher Davis
- Federico Mena Quintero
- Michael Downey
- Rosanna Yuen
All the members of the CoC Committee have completed Code of Conduct Incident Response training provided by Otter Tech, and are professionally trained to handle incident reports in GNOME community events.
The committee has an email address that can be used to send reports: conduct@gnome.org as well as a website for report submission: https://conduct.gnome.org/
ReportsSince July 2024, the committee has received reports on a total of 19 possible incidents. Of these, 9 incidents were determined to be actionable by the committee, and were further resolved during the reporting period.
- Report about an individual in a GNOME Matrix room acting rudely toward others. A Committee representative discussed the issue with the reported individual and adjusted room permissions.
- Report about an individual acting in a hostile manner toward a new GNOME contributor in a community channel. A Committee representative contacted the reported person to provide a warning and to suggest methods of friendlier engagement.
- Report about a discussion on a community channel that had turned heated. After going through the referenced conversation, the Committee noted that all participants were using non-friendly language and that the turning point in the conversation was a disagreement over a moderator’s action. The committee contacted the moderator and reminded them to use kinder words in the future.
- Report related to technical topics out of the scope of the CoC committee. The issue was forwarded to the Board of Directors.
- Report about members’ replies in community channels; after reviewing the conversation the CoC committee decided that it was not actionable. The conversation did not violate the Code of Conduct.
- Report about inappropriate and insulting comments made by a member in social moments during an offline event. The CoC Committee sent a warning to the reported person.
- Report against two members making comments the reporter considered disrespectful in a community channel. After reading through the conversation, the Committee did not see any violations to the CoC. No actions were taken.
- Report on someone using abrasive and aggressive language in a community channel. After reading the conversation, the Committee agrees with this assessment. As this person had previously been found to have violated the CoC, the Committee has banned the person from the channel for one month.
- Report about ableist language in a GitLab merge request. The reported person was given warning not to use such language.
- Report against GNOME in general without any specifics. A request for more information was sent, and after no reply after a number of months, the issue has been closed with no action.
- Report against the moderating team’s efforts to keep discussions within the Code of Conduct. No action was taken.
- Report about a contributor being aggressive to the reporter who is working with them, on multiple occasions. The CoC committee talked both to the reporter and the reported person, and also to other people working with them in order to solve the disagreements. The result was that the reporter had some patterns on their behavior that made it difficult to collaborate with them too. The conclusion was that all parties acknowledged their wrong behaviors and will work on improving that and be more collaborative.
- Report about a disagreement with a maintainer’s decision. The report was non-actionable.
- Report about a contributor who set up harassment campaigns against Foundation and non-Foundation members. This person has been suspended indefinitely from participation in GNOME.
- Report about a moderator being hostile in community channels; this was not the first report we received about this member so they got banned from the channel.
- Report about a blog syndicated in planet.gnome.org. The committee evaluated the blog in question and found it not to contravene the CoC, so it took no action afterwards.
- Five reports, unrelated to each other, with technical support requests. These were marked as not actionable.
- Report with a general comment about GNOME, marked as not actionable.
- A question about where to report security issues; informed the reporter about security@gnome.org.
The Foundation’s Executive Director commissioned an external review of the CoC Committee’s procedures in October of 2024. After discussion with the Foundation Board of Directors, we have made the following changes to the committee procedures:
- Establish a “chain of command” for requesting tasks to be performed by sysadmins after an incident report.
- Clarify the procedures for notifying affected people and teams or committees after a report.
- Clarify the way notifications are made about a report’s consequences, and update the Committee’s communications infrastructure in general.
- Specify how to handle reports related to Foundation staff or contractors.
The history of changes can be seen in this merge request to the repository for the Code of Conduct.
CoC Committee blogWe have a new blog at https://conduct.gnome.org/blog/, where you can read this transparency report. In the future, we hope to post materials about dealing with interpersonal conflict, non-violent communication, and other ideas to help the GNOME community.
Meetings of the CoC committeeThe CoC committee has two meetings each month for general updates, and weekly ad-hoc meetings when they receive reports. There are also in-person meetings during GNOME events.
Ways to contact the CoC committee- https://conduct.gnome.org – contains the GNOME Code of Conduct and a reporting form.
- conduct@gnome.org – incident reports, questions, etc.
Ignacy Kuchciński: Using Portals with unsandboxed apps
- Writing universal code: you don't need to care about writing desktop-specific code, as different desktops and toolkits will provide their own implementations
- Respecting the privacy of the user: portals use a permission system, which can be granted, revoked and controlled by the user. While host apps could bypass them, user can still be presented with dialogs, which will ask for permission to perform certain actions or obtain information.
Okay, so they seem like a good idea after all. Now, how do we use them?More often than not, you don't actually have to manually call the D-Bus API - for many of the portals, toolkits and desktop will interact with them on your behalf, exposing easy to use high-level APIs. For example, if you're developing an app using GTK4 on GNOME and want to inhibit suspend or logout, you would call gtk_application_inhibit which will actually prefer using the Inhibit portal over directly talking to gnome-session-manager. There are also convenience libraries to help you, available for different programming languages.
That sounds easy, is that all? Unfortunately, there are some caveats.The fact that we can safely say that flatpaks are first-class citizen when interacting with portals, compared to host apps, is a good thing - they offer many benefits, and we should embrace them. However, in the real world there are many instances of apps installed without sandbox, and the transition will take time, so in the meantime we need to make sure they play correctly with portals as well.
One such instance is the getting the information about the app - in flatpak land, it's obtained from a special .flatpak-info file located in the sandbox. In the host apps though, xdg-desktop-portal tries to parse the app id from the systemd unit name, only accepting "app-" prefixed format, specified in the XDG standardization for applications. This works for some applications, but unfortunately not all, at least at this time. One such example is D-Bus activated apps, which are started with "dbus-" prefixed systemd unit name, or the ones started from the terminal with even different prefixes. In all those cases, the app id exposed to the portal is empty.
One major problem, when xdg-desktop-portal doesn't have access to the app-id, is undoubtedly failure of inhibiting logout/suspend when using the Inhibit portal. Applications on GNOME using GTK4 will call gtk_application_inhibit, which in turn calls xdg-desktop-portal-gtk inhibit portal implementation, which finally talks to the gnome-session-manager D-Bus API. However, it requires app-id to function correctly, and will not inhibit the session without it. The situation should get better in the next release of gnome-session but it could still cause problems for the user, not knowing the name of the application that is preventing logout/suspend.
Moreover, while not as critical, other portals also rely on that information in some way. Account portal used for obtaining the information about the user will mention the app display name when asking for confirmation, otherwise will call it the "requesting app", which the user may not recognize, and is more likely to cancel. Location portal will do the same, and Background portal won't allow autostart if it's requested.
GNOME Shell logout dialog when Nautilus is copying files, inhibiting indirectly via portal
How can we make sure our host apps play well with portals?Fortunately, there are many ways to make sure your host app interacts correctly with portals. First and foremost, you should always try to follow the XDG cgroup pathname standardization for applications. Most desktop environments already follow the standard, and if they don't, you should definitely report it as a bug. There are some exceptions, however - D-Bus activated apps are started by the D-Bus message bus implementations on behalf of desktops, and currently they don't put the app in the correct systemd unit. There is an effort to fix that on the dbus-broker side, but these things take time, and there is also the case of apps started from the terminal, which have different unit names altogether.
When for some reason your app was launched in a way that doesn't follow the standard, you can use the special interface for registering with XDG Desktop Portal, the host app Registry, which overwrites the automatic detection. It should be considered a temporary solution, as it is expected to be eventually deprecated (with the details of the replacement specified in the documentation), nevertheless it lets us fix the problem at present. Some toolkits, like GTK, will register the application for you, during the GtkApplication startup call.
There is one caveat, though - it needs to be the first call to the portal, otherwise it will not overwrite the automatic detection. This means that when relying on GTK to handle the registration, you need to make sure you don't interact with the portal before the GtkApplication startup chain-up call. So no more gtk_init in main.c, which on Wayland uses Settings portal to open display, all such code needs to be moved just after the application startup chain-up. If for some reason you really cannot do that, you'll have to call the D-Bus method yourself, before any portal interaction is made.
The end is never the end...If you made it this far, congratulations and thanks for taking this rabbit hole with me. If it's still not enough, you can check out the ticket I reported and worked on in nautilus, giving even more context to how we ended up here. Hope you learned something that will make your app better :)
Tobias Bernard: Summer of GNOME OS
So far, GNOME OS has mostly been used for testing in virtual machines, but what if you could just use it as your primary OS on real hardware?
Turns out you can!
While it’s still early days and it’s not recommended for non-technical audiences, GNOME OS is now ready for developers and early adopters who know how to deal with occasional bugs (and importantly, file those bugs when they occur).
The ChallengeTo get GNOME OS to the next stage we need a lot more hardware testing. This is why this summer (June, July, and August) we’re launching a GNOME OS daily-driving challenge. This is how it works:
- 10 points for daily driving GNOME OS on your primary computer for at least 4 weeks
- 1 point for every (valid, non-duplicate) issue created
- 3 points for every (merged) merge request
- 5 points for fixing an open issue
You can sign up for the challenge and claim points by adding yourself to the list of participants on the Hedgedoc. As the challenge progresses, add any issues and MRs you opened to the list.
The person with the most points on September 1 will receive a OnePlus 6 (running postmarketOS, unless someone gets GNOME OS to work on it by then). The three people with the most points on September 1 (noon UTC) will receive a limited-edition shirt (stay tuned for designs!).
Important links:
- Sign up for the challenge by adding yourself to the list of participants.
- To install GNOME OS on real hardware follow the installation instructions.
- For questions and problems, use the GNOME OS Matrix channel.
- File any GNOME OS issues you encounter here.
Using GNOME OS Nightly means you’re running the latest latest main for all of our projects. This means you get all the dope new features as they land, months before they hit Fedora Rawhide et al.
For GNOME contributors that’s especially valuable because it allows for easy testing of things that are annoying/impossible to try in a VM or nested session (e.g. notifications or touch input). For feature branches there’s also the possibility to install a sysext of a development branch for system components, making it easy to try things out before they’ve even landed.
More people daily driving Nightly has huge benefits for the ecosystem, because it allows for catching issues early in the cycle, while they’re still easy to fix.
Is my device supported?Most laptops from the past 5 years are probably fine, especially Thinkpads. The most important specs you need are UEFI and if you want to test the TPM security features you need a semi-recent TPM (any Windows 11 laptop should have that). If you’re not sure, ask in the GNOME OS channel.
Does $APP work on GNOME OS?Anything available as a Flatpak works fine. For other things, you’ll have to build a sysext.
Generally we’re interested in collecting use cases that Flatpak doesn’t cover currently. One of the goals for this initiative is finding both short-term workarounds and long-term solutions for those cases.
Please add such use cases to the relevant section in the Hedgedoc.
Any other known limitations?GNOME OS uses systemd-sysupdate for updating the system, which doesn’t yet support delta updates. This means you have to download a new 2GB image from scratch for every update, which might be an issue if you don’t have regular access to a fast internet connection.
The current installer is temporary, so it’s missing many features we’ll have in the real installer, and the UI isn’t very polished.
Anything else I should know before trying to install GNOME OS?Update the device’s firmware, including the TPM’s firmware, before nuking the Windows install the computer came with (I’m speaking from experience)!
I tried it, but I’m having problems :(Ask in the GNOME OS Matrix channel!
Elizabeth K. Joseph: A VisionFive 2 and a Raspberry Pi 1 B
A couple weeks ago I was playing around with a multiple architecture CI setup with another team, and that led me to pull out my StarFive VisionFive 2 SBC again to see where I could make it this time with an install.
I left off about a year ago when I succeeded in getting an older version of Debian on it, but attempts to get the tooling to install a more broadly supported version of U-Boot to the SPI flash were unsuccessful. Then I got pulled away to other things, effectively just bringing my VF2 around to events as a prop for my multiarch talks – which it did beautifully! I even had one conference attendee buy one to play with while sitting in the audience of my talk. Cool.
I was delighted to learn how much progress had been made since I last looked. Canonical has published more formalized documentation: Install Ubuntu on the StarFive VisionFive 2 in the place of what had been a rather cluttered wiki page. So I got all hooked up and began my latest attempt.
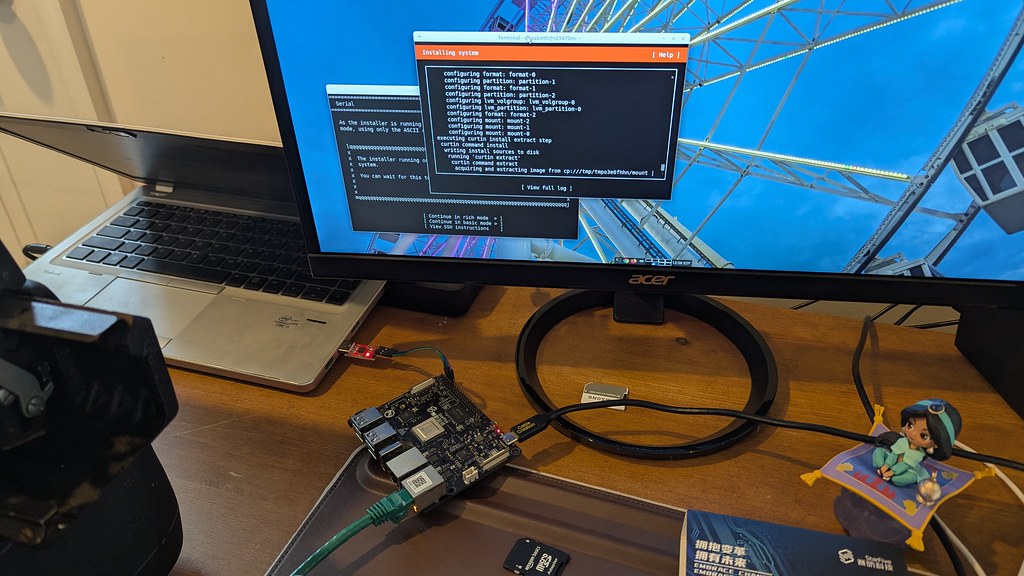{kind=link}
My first step was to grab the pre-installed server image. I got that installed, but struggled a little with persistence once I unplugged the USB UART adapter and rebooted. I then decided just to move forward with the Install U-Boot to the SPI flash instructions. I struggled a bit here for two reasons:
- The documentation today leads off with having you download the livecd, but you actually want the pre-installed server image to flash U-Boot, the livecd step doesn’t come until later. Admittedly, the instructions do say this, but I wasn’t reading carefully enough and was more focused on the steps.
- I couldn’t get the 24.10 pre-installed image to work for flashing U-Boot, but once I went back to the 24.04 pre-installed image it worked.
And then I had to fly across the country. We’re spending a couple weeks around spring break here at our vacation house in Philadelphia, but the good thing about SBCs is that they’re incredibly portable and I just tossed my gear into my backpack and brought it along.
Thanks to Emil Renner Berthing (esmil) on the Ubuntu Matrix server for providing me with enough guidance to figure out where I had gone wrong above, and got me on my way just a few days after we arrived in Philly.
With the newer U-Boot installed, I was able to use the Ubuntu 24.04 livecd image on a micro SD Card to install Ubuntu 24.04 on an NVMe drive! That’s another new change since I last looked at installation, using my little NVMe drive as a target was a lot simpler than it would have been a year ago. In fact, it was rather anticlimactic, hah!
{kind=link}
And with that, I was fully logged in to my new system.
elizabeth@r2kt:~$ cat /proc/cpuinfo
processor : 0
hart : 2
isa : rv64imafdc_zicntr_zicsr_zifencei_zihpm_zba_zbb
mmu : sv39
uarch : sifive,u74-mc
mvendorid : 0x489
marchid : 0x8000000000000007
mimpid : 0x4210427
hart isa : rv64imafdc_zicntr_zicsr_zifencei_zihpm_zba_zbb
It has 4 cores, so here’s the full output: vf2-cpus.txt
What will I do with this little single board computer? I don’t know yet. I joked with my husband that I’d “install Debian on it and forget about it like everything else” but I really would like to get past that. I have my little multiarch demo CI project in the wings, and I’ll probably loop it into that.
Since we were in Philly, I had a look over at my long-neglected Raspberry Pi 1B that I have here. When we first moved in, I used it as an ssh tunnel to get to this network from California. It was great for that! But now we have a more sophisticated network setup between the houses with a VLAN that connects them, so the ssh tunnel is unnecessary. In fact, my poor Raspberry Pi fell off the WiFi network when we switched to 802.1X just over a year ago and I never got around to getting it back on the network. I connected it to a keyboard and monitor and started some investigation. Honestly, I’m surprised the little guy was still running, but it’s doing fine!
And it had been chugging along running Rasbian based on Debian 9. Well, that’s worth an upgrade. But not just an upgrade, I didn’t want to stress the device and SD card, so I figured flashing it with the latest version of Raspberry Pi OS was the right way to go. It turns out, it’s been a long time since I’ve done a Raspberry Pi install.
I grabbed the Raspberry Pi Imager and went on my way. It’s really nice. I went with the Raspberry Pi OS Lite install since it’s the RP1, I didn’t want a GUI. The imager asked the usual installation questions, loaded up my SSH key, and I was ready to load it up in my Pi.
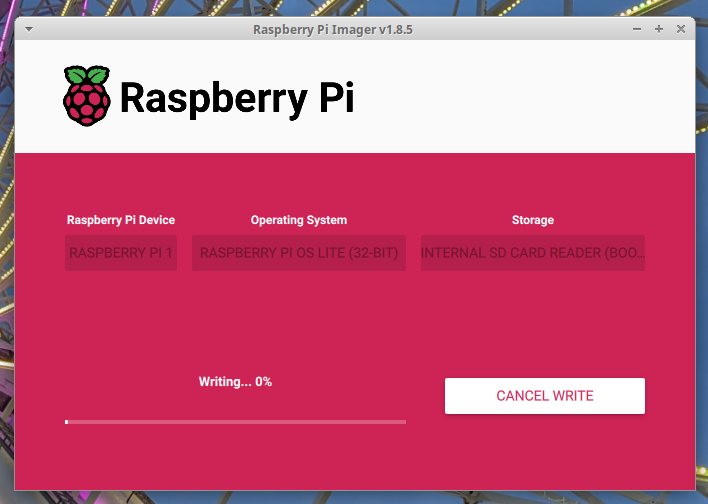{kind=link}
The only thing I need to finish sorting out is networking. The old USB WiFi adapter I have it in doesn’t initialize until after it’s booted up, so wpa_supplicant on boot can’t negotiate with the access point. I’ll have to play around with it. And what will I use this for once I do, now that it’s not an SSH tunnel? I’m not sure yet.
{kind=link}
I realize this blog post isn’t very deep or technical, but I guess that’s the point. We’ve come a long way in recent years in support for non-x86 architectures, so installation has gotten a lot easier across several of them. If you’re new to playing around with architectures, I’d say it’s a really good time to start. You can hit the ground running with some wins, and then play around as you go with various things you want to help get working. It’s a lot of fun, and the years I spent playing around with Debian on Sparc back in the day definitely laid the groundwork for the job I have at IBM working on mainframes. You never know where a bit of technical curiosity will get you.
Lubuntu Blog: Lubuntu Plucky Puffin Beta Released!
Faqet
- « e para
- ‹ paraardhëse
- 1
- 2
- 3
- 4